Agentic Data Science: Three Pillars of Trustworthy AI Agents
Code Is Solved. Judgment Is Not.
Building a reliable AI coder is a solved problem. Tools like Claude Code can produce near-production-ready systems from a few prompts. The syntax works, the tests pass, the features ship.
Building a reliable AI data scientist? Not solved. Not even close.
I’ve been in data science for 15 years, and the pace of AI-driven change keeps surprising me. But I’ve also seen where it breaks down in ways that matter. A few months ago, a post went viral on Reddit: a company had been using an AI agent to answer leadership questions about metrics since November. It seemed great at first. Fast answers, detailed explanations, everyone loved it. Then someone asked to double-check a number.
What they found: the AI had been fabricating analytics data for three months. The VP of Sales had made territory decisions based on numbers that didn’t exist. The CFO showed the board a deck built on hallucinated percentages.
The code was flawless. The conclusions were garbage.
This is the core problem. When you build an AI data scientist, you’re not shipping code. You’re shipping judgment. The agent needs to handle ambiguity, reason causally about what drives what, and admit when the data doesn’t support a conclusion.
The Garden of Forking Paths
Why do LLMs fail at these judgment calls?
A recent paper by Bertran, Fogliato, and Wu (2026) makes the problem concrete. They deployed autonomous AI analysts on fixed datasets, varying the model and prompt conditions. The agents independently built and executed full analysis pipelines. The result: wide dispersion in effect sizes, p-values, and binary conclusions, with different runs frequently reversing whether a hypothesis was supported. Changing just the analyst persona shifted hypothesis support by 47%.
The problem is structural. Any data analysis involves a cascade of micro-decisions: How do you handle missing values? Remove outliers or keep them? Log-transform or not? Linear model, random forest, or Bayesian hierarchical? Each choice forks the path, and the forks compound.
An experienced data scientist navigates this decision tree using judgment built over years. They know which paths lead to reliable conclusions and which lead to plausible-sounding nonsense. An LLM explores this space probabilistically. It often lands on results wrapped in clean code and confident language that are just wrong.
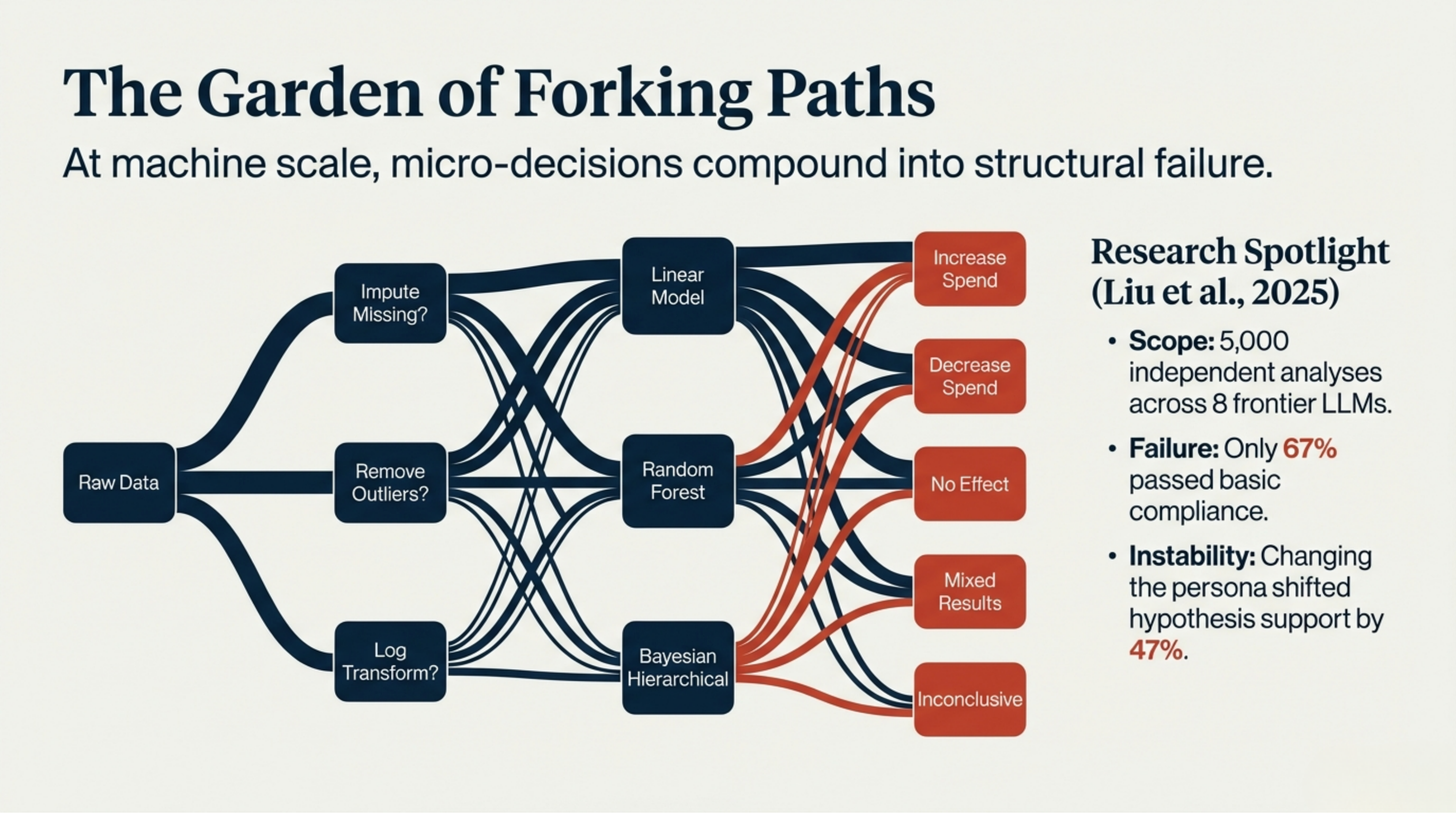
This is what makes agentic data science harder than agentic coding. In coding, there’s usually a clear target: the code compiles, the tests pass, the feature works as specified. In data science, the output can be completely wrong and still look polished.
Three Pillars of Trustworthy Agents
I’ve spent the past year thinking about how to build agentic data science systems that organizations can actually rely on. I keep coming back to three pillars.
Constraints (Skills). Domain expertise encoded to limit the forking paths of analysis. Move from generative creativity to constrained reliability.
Measurement. Continuous benchmarks against ground truth. Not vibes. Not “does the code run.”
Epistemic Humility. Using Bayesian methods to know, and say, when the agent doesn’t know.

Pillar 1: Constraints as Code
The first pillar is about narrowing the space of possible analyses to the subset that domain experts would consider valid.
A skill is a validated playbook, not a prompt. It’s a structured document that specifies, at runtime within the agent’s context, how to approach certain classes of problems. A good skill includes mandatory diagnostics the agent must run, preferred model structures for specific problem types, and Bayesian priors that encode domain knowledge. The output gets constrained by this knowledge.
Think of it as the difference between asking a random person to diagnose your car versus taking it to a certified mechanic. The mechanic has a checklist, knows the common failure modes, and follows a diagnostic protocol. The random person might get lucky, or might confidently tell you to replace your transmission when the problem is a loose gas cap.
Does This Actually Work?
My colleague Chris Fonnesbeck at PyMC Labs ran a controlled experiment to find out. He tested Claude Code on five Bayesian modeling tasks of increasing difficulty, from a standard hierarchical model (easy) through stochastic volatility and sparse variable selection (hard). Each task was run three times in two conditions: vanilla Claude Code with no guidance, and Claude Code equipped with a PyMC modeling skill containing about 4,500 tokens of domain expertise.
The headline: the skill made the difference between a crash and a result.
| No Skill | With Skill | |
|---|---|---|
| Viability (working, converged model) | 60% | 93% |
| Quality score (out of 30) | 21.3 | 25.2 |
| Effect size (Cohen’s d) | 1.16 (large) |
On easy tasks (hierarchical models, ordinal regression), both conditions did fine. On hard tasks, the results diverged sharply. For stochastic volatility, the vanilla agent produced zero converged models across three attempts. With the skill, two of three runs succeeded. For sparse variable selection with horseshoe priors, viability jumped from 33% to 100%.
The pattern: skills help most where they’re needed most. On hard, specialized problems where the LLM’s general training runs thin.
For the full methodology, scoring rubric, and task-by-task analysis, see Chris’s detailed write-up on the PyMC Labs blog.
Pillar 2: Measurement
Most agentic data science systems today are evaluated on vibes. Does the output look reasonable? Did the code run without errors? That bar is too low.
Chris’s benchmark scored each run on six criteria: whether the model produced complete inference data, whether chains converged (R-hat, effective sample size, divergences), whether the model was appropriate for the problem, whether it followed best practices, how much the agent thrashed through error-fix cycles, and total efficiency. Four of these six were automated checks, which means you can run them on every single agent output.
Beyond benchmarking, any production deployment needs what I call a verification stack: layers of checks that catch different types of errors.
- Execution. Does the code run? Table stakes. The dangerous errors don’t throw exceptions.
- Diagnostics. Does the model converge? Check R-hat values, effective sample sizes, divergence counts.
- Predictive checks. Does the model match reality? Prior and posterior predictive checks against observed data.
- Sensitivity. Do conclusions hold up under reasonable alternative assumptions? If they flip, the findings aren’t robust.
- Human checkpoints. Does this pass the smell test? Some checks need human judgment: are effect sizes realistic, is the business interpretation sound, are we answering the right question?
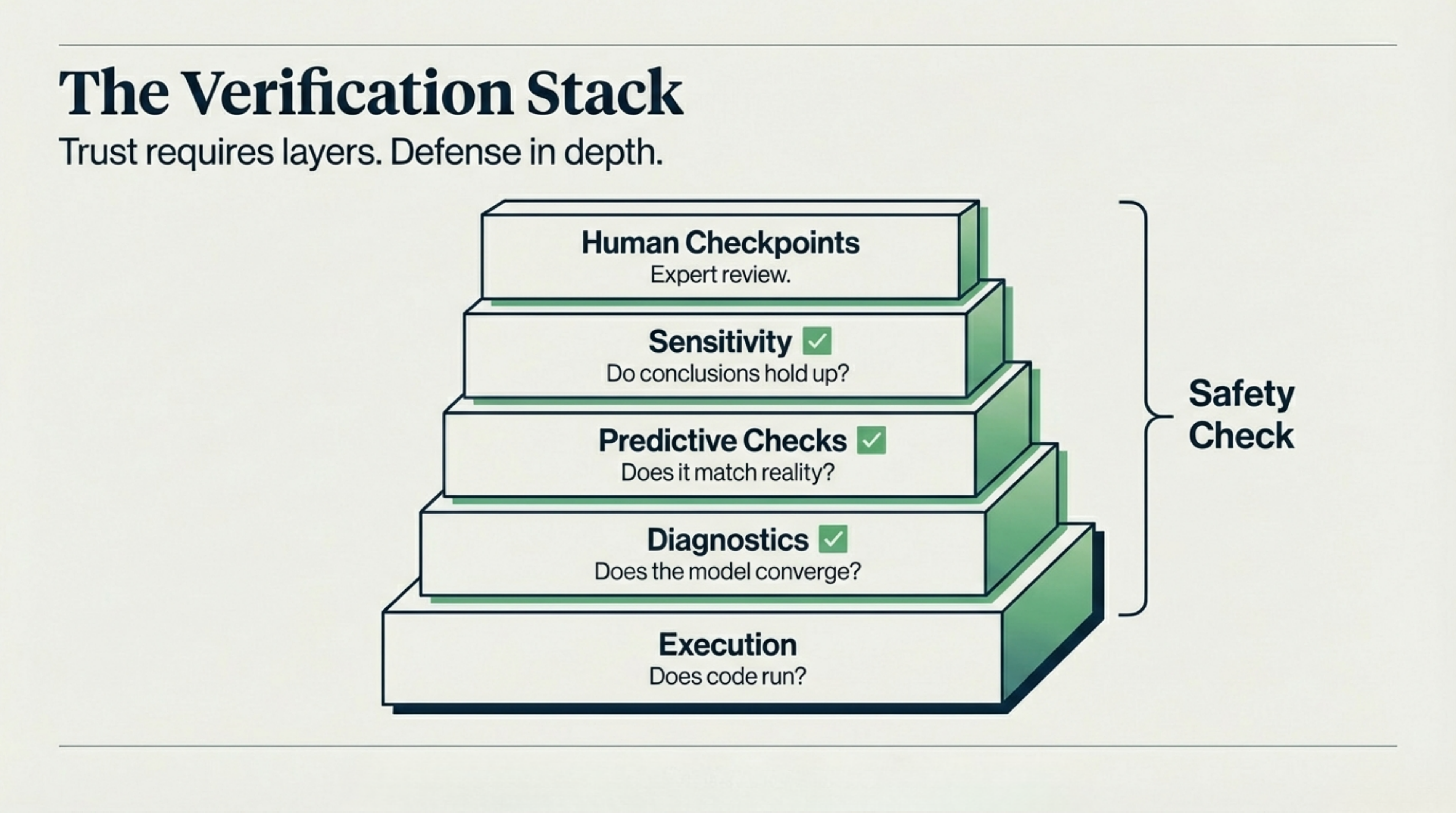
Each layer catches a different class of failure. Skip any layer and you’re exposed to errors that the layers below can’t detect.
Pillar 3: The Power of “I Don’t Know”
This is the pillar I care about most.
When an agentic system delivers a business recommendation, the stakeholder needs to know how much to trust it. A point estimate (“Channel A has 3.2x ROI”) gives false precision. It hides the uncertainty behind a single number.
Bayesian methods aren’t a philosophical preference here. They’re an engineering requirement for trustworthy agents.
A Bayesian posterior gives you the full range of plausible values: “Channel A ROI: 50% credible interval [1.8, 2.9], 94% credible interval [1.2, 3.5].” When the data is ambiguous, the posterior reflects that ambiguity. The agent cannot hide behind a confident number.
This matters most when the data is noisy and the signal is weak. We tested this at PyMC Labs with a marketing mix modeling scenario designed to be a trap: weak signal, high noise, correlated channels. The kind of data where the honest answer is “I can’t tell.”
The vanilla agent, without skills or Bayesian constraints, recommended reallocating 100% of budget to TV. Confident. Specific. Completely wrong. The data didn’t support any reallocation at all.
The skilled agent, equipped with Bayesian methods and proper uncertainty quantification, gave a different answer: “The signal is too weak to support reallocation. Uncertainties are high. I recommend gathering more data before acting.”
A confident wrong recommendation is infinitely more expensive than an honest “I’m not sure.” Saying “I don’t know” is the single most valuable thing an agent can do when the data is ambiguous. Bayesian methods make that possible.
From Ideas to Practice
We’re already building the infrastructure behind these ideas.
At Decision AI, we develop domain-specific agents with built-in governance for high-stakes domains: marketing analytics, financial modeling, clinical research. The focus is on skill engineering, validation, and compliance frameworks that make agentic data science safe for the enterprise.
We’ve also launched Decision Hub, an open registry with over 2,000 validated skills from dozens of organizations. Unlike general-purpose collections, the hub is tailored to data science and analytics. Skills are continuously benchmarked, security-graded, and documented. The idea: don’t build domain expertise from scratch. Install validated expertise, then verify it works before your agent uses it in production.
The Future Is Scaled Judgment
Agentic data science is real and moving fast. But the gap between “impressive demo” and “system I’d trust with business decisions” remains wide.
The organizations that close this gap won’t be the ones with the most agents. They’ll be the ones that take the three pillars seriously: constraints that encode real expertise, measurement that goes beyond “does it run,” and the epistemic humility to say “I don’t know” when the data requires it.
Scaling judgment, not just automation. That’s what this field is really about.
References
- Bertran, M., Fogliato, R., & Wu, Z. S. (2026). “Many AI Analysts, One Dataset: Navigating the Agentic Data Science Multiverse.” arXiv:2602.18710
- Fonnesbeck, C. (2026). “Improving AI Agent Performance with Domain Skills.” PyMC Labs Blog
- PyMC
- Decision AI
- Decision Hub
- Webinar: Agentic Data Science with PyMC Labs (video)