I ran 25 experiments on AI brainstorming. More agents beat better prompts.
AI brainstorming has a sameness problem
Ask Claude to brainstorm 20 product ideas for remote workers and you’ll get 20 competent, well-structured ideas that all live in the same neighborhood. Ergonomic cushions, cable organizers, desk lamps with USB ports. Variations on a theme.
The ideas are fine. The problem is they’re all fine in the same way. When you’re searching for something new, diversity matters more than average quality.
Idea generation is like searching a mountain range at night with a flashlight. The terrain has peaks and valleys scattered unpredictably. If you send all your scouts down the same path, you’ll find the tallest hill on that path. But the actual highest peak might be three ridges over, in a direction nobody thought to look.
Researchers at Wharton (Meincke, Mollick, and Terwiesch) published a paper in 2024 that measured this problem precisely and found a prompting technique that mostly fixes it. I took their findings, ran 25 experiments of my own, and discovered something they didn’t test: throwing more agents at the problem works far better than I expected.
What the Wharton paper found
The researchers tested 35 different prompting strategies on GPT-4, asking each to generate product ideas for college students. They measured diversity using cosine similarity between ideas (lower means more diverse).
| Strategy | Cosine similarity |
|---|---|
| Group of human students | 0.243 |
| Chain-of-Thought prompting | 0.255 |
| “Creative Entrepreneur” persona | 0.348 |
| Steve Jobs persona | 0.368 |
| Plain prompt, no engineering | 0.377 |
| Seeded with previous good ideas | 0.403 |
| Told about similarity scores | 0.432 |
Chain-of-Thought (CoT) nearly matched human diversity and blew past everything else. The prompt has a specific three-step structure. First generate 100 short titles, exploring freely without committing to any of them. Then review the list and push ideas to be bolder and more different from each other. Then add descriptions. The separation matters: when producing titles only, the model doesn’t self-censor because it hasn’t invested in elaborating anything yet.
What surprised me more was what failed. Telling the model to “think like Steve Jobs” barely moved the needle compared to no prompting at all (0.368 vs 0.377). Feeding it Harvard Business Review articles on brainstorming made things worse (0.387). The absolute worst strategy was telling the model how similar its existing ideas were and asking it to be different (0.432). Instead of exploring, it tried to game the similarity metric.
The paper left a question open
The researchers tested each strategy independently. One prompt, one session, one pool of ideas. But they also measured something interesting: the overlap between idea pools from different strategies was low. A “Steve Jobs” session and a “Creative Entrepreneur” session produced mostly different ideas. This suggests that combining pools might outperform any single strategy, but they never tested it.
I wanted to find out what happens when you do.
My experiment setup
I built a benchmark script that runs each strategy as an isolated claude -p process, so there’s true context isolation between agents. No shared conversation history, no anchoring. For multi-agent strategies, all agents run in parallel and a separate merge step curates the combined pool.
I tested five strategies across five different brainstorming prompts:
- “Brainstorm ideas for a new physical product for remote workers, priced under $100”
- “I run a small digital marketing agency with 5 employees. Give me ideas for new revenue streams beyond client work”
- “I need ideas for a YouTube channel about personal finance that would actually stand out in 2026”
- “I’m building a habit-tracking app. Give me ideas for features that would differentiate it from competitors like Streaks and Habitica”
- “Brainstorm creative marketing campaign ideas for a new plant-based protein bar targeting gym-goers aged 25-40”
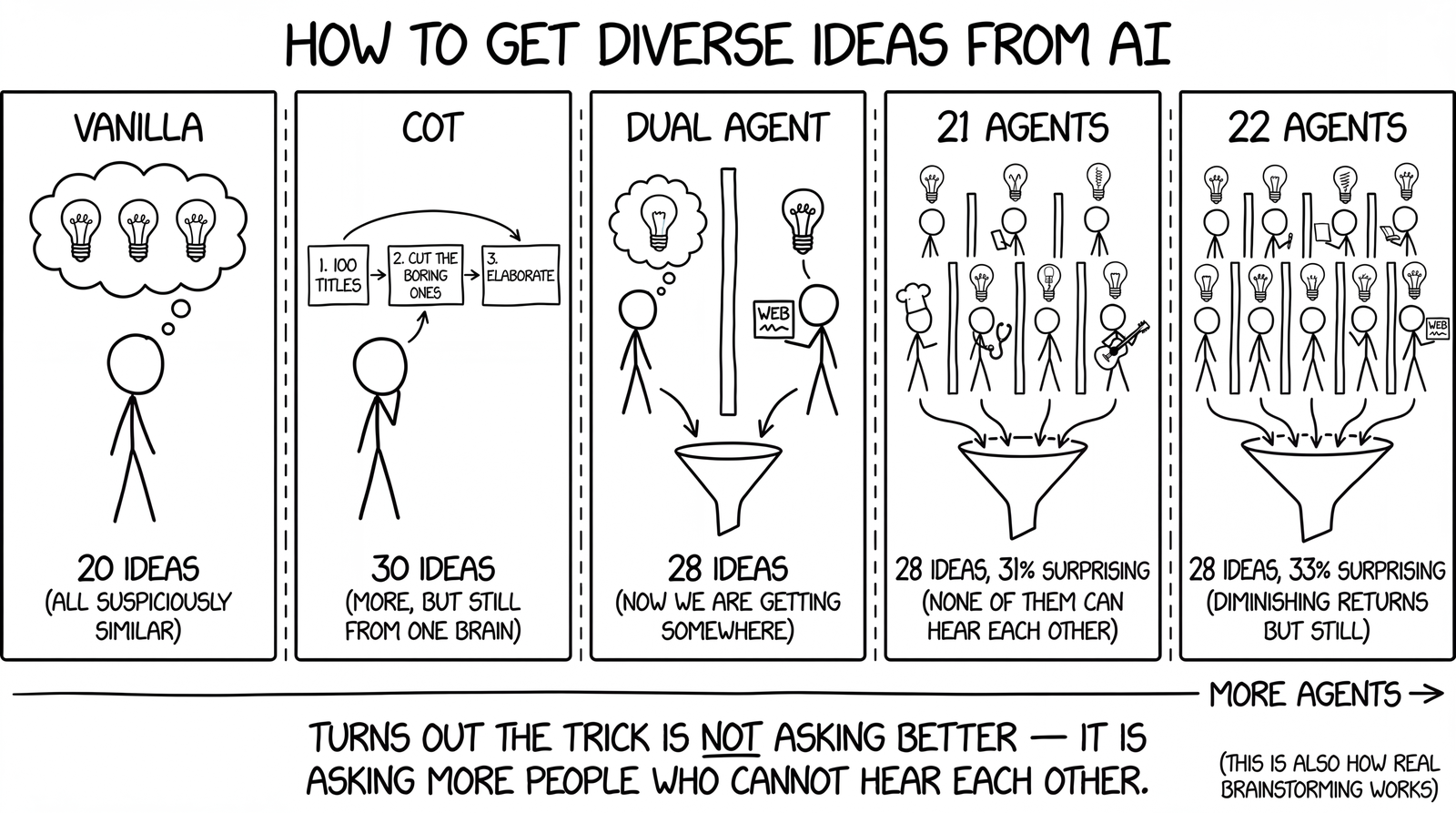
The five strategies, from simplest to most complex:
Vanilla. Just ask Claude to brainstorm. No special prompting.
CoT-only. The paper’s three-step prompt: generate 100 titles, self-critique for boldness, select and describe the best 30. One agent.
Dual-agent. Two parallel agents. Agent A runs pure CoT with no external input. Agent B first searches the web for what exists, what gaps remain, and what users complain about, then runs CoT informed by that research. A merge step curates the combined pool into ~28 ideas with a Wild Cards section.
CoT + multi-agent (cot_multi). One CoT agent plus 10 dynamically generated personas and 10 creativity techniques, all running as separate isolated processes. 21 agents total. The personas are generated fresh for each problem by a separate call that picks roles far from the problem domain. The 10 techniques are SCAMPER, Constraint Removal, Analogical Transfer, Random Entry, First Principles, Reverse Brainstorming, Worst Possible Idea, Six Thinking Hats, Biomimicry, and Time Travel. All 21 agents run in parallel, then a merge step curates to ~28 ideas.
Full combo. Everything above: CoT + Informed CoT + 10 personas + 10 techniques. 22 agents total.
I graded each run on idea count, how many ideas were genuinely surprising (graded strictly by an independent LLM), how many were grounded in real-world research, thematic cluster count, domain spread, and whether the output preserved a Wild Cards section.
The results
| Metric | vanilla | cot_only | dual_agent | cot_multi | full_combo |
|---|---|---|---|---|---|
| Ideas output | 20.6 | 30.0 | 28.0 | 28.0 | 28.0 |
| Surprising ideas | 4.4 | 4.6 | 5.8 | 8.6 | 9.2 |
| Surprise rate | 21.4% | 15.3% | 20.7% | 30.7% | 32.9% |
| Research-grounded | 4.0 | 6.4 | 7.4 | 10.0 | 10.6 |
| Wild Cards | 5/5 | 0/5 | 5/5 | 5/5 | 5/5 |
| Thematic clusters | 7.4 | 10.4 | 9.8 | 12.4 | 12.0 |
| Domain spread | 8.4 | 10.4 | 10.4 | 13.0 | 13.0 |
| Duplicate-free | 5/5 | 5/5 | 5/5 | 5/5 | 5/5 |
| Wall-clock time | 165s | 92s | 196s | 207s | 260s |
| Total tokens | 86K | 28K | 179K | 613K | 751K |
The jump from dual_agent to cot_multi is the story. Going from 2 agents to 21, the surprise rate goes from 20.7% to 30.7%. Research-grounded ideas go from 7.4 to 10. Thematic clusters go from 9.8 to 12.4. Almost every quality metric improves meaningfully.
Full combo (22 agents) edges out cot_multi (21 agents) on most metrics, but the margin is thin: 32.9% vs 30.7% surprise rate. Adding the Informed CoT agent on top of 21 others buys you +2.2 percentage points of novelty for +22% more tokens. Not a great trade in most situations.
What I actually learned from looking at the outputs
Numbers tell part of the story. Reading through the actual idea sets made the difference visceral in a way the metrics don’t fully convey.
For the habit-tracking app prompt, vanilla produced ideas like “streak flexibility mode” and “habit correlation dashboard.” Perfectly reasonable. The cot_multi run, with its addiction counselor persona, produced “the slip-vs-relapse firewall” (borrowed directly from relapse prevention psychology, distinguishing between a missed day and a pattern breakdown). The Nintendo game designer persona produced “fog-of-war calendar” (hiding future dates so you can’t feel overwhelmed by the blank days ahead). The First Principles technique stripped tracking to fundamentals and rebuilt it as “body-as-controller” where physical movements detected by your phone replace manual logging entirely.
A vanilla brainstorm would never produce any of these. They come from professional lenses that have nothing to do with habit tracking but everything to do with how humans actually change behavior.
The persona generation step matters
For cot_multi and full_combo, the personas aren’t hardcoded. A separate LLM call generates 10 domain-distant personas specifically for each problem. For the marketing campaign prompt, it picked a combat sports nutritionist (athletes who distrust marketing claims) and a Bangkok street food vendor (sensory experience, impulse mechanics). For the app features prompt, an addiction counselor and a Nintendo game designer.
The quality of these personas varies across runs. I suspect this explains some of the per-prompt variance in the results. When the persona generator picks roles that are far from the domain but structurally parallel, the ideas are strong. When it picks something too adjacent, that persona’s output just echoes CoT.
Things that didn’t work the way I expected
CoT-only has a lower surprise rate than vanilla. This stopped me cold. CoT produces 30 curated ideas with a 15.3% surprise rate. Vanilla produces 21 ideas with a 21.4% surprise rate. The CoT prompt doesn’t produce more creative ideas per attempt. It produces more attempts. In the paper’s setup, where you measure pool diversity across 100 ideas, that’s enough. In practice, when you’re curating down to 28 ideas, the per-idea surprise rate is what you feel.
Adding web research to CoT anchors it. In earlier experiments, I tested having the model search the web before running CoT. It produced ideas grounded in real market data, which was useful, but the surprise rate dropped from 14.2% to 10.4%. Research gives the model more conventional starting points. The self-critique step doesn’t fully compensate. The fix was running a research agent in parallel with a pure CoT agent, so the research informs but doesn’t constrain the overall pool.
The merge step is doing real work. With 21 agents producing ~15 ideas each, you get ~300 raw ideas with significant overlap. The merge step deduplicates, clusters by theme, and selects for maximum diversity. Without it, you’d have a mess. With it, you get a clean 28-idea set organized by theme with a Wild Cards section. The merge agent sees all ideas at once and can pick the most interesting one from each cluster rather than the most common.
The cost question
The honest version of the results table should include cost.
| Strategy | Agents | Surprise rate | Tokens | Approx. cost |
|---|---|---|---|---|
| cot_only | 1 | 15.3% | 28K | ~$0.08 |
| dual_agent | 2 | 20.7% | 179K | ~$0.54 |
| cot_multi | 21 | 30.7% | 613K | ~$1.84 |
| full_combo | 22 | 32.9% | 751K | ~$2.25 |
Going from cot_only to cot_multi gets you 2x the surprise rate for roughly 22x the token cost. Whether that’s worth it depends on the stakes. For naming a company or defining a product strategy, spending $1.50 on ideas that are twice as likely to be surprising seems cheap. For brainstorming blog topics on a Tuesday afternoon, the CoT prompt by itself is fine.
What the paper got right, and what it missed
The Wharton paper’s core finding holds up: the CoT prompt structure (generate many, self-critique, elaborate) is the foundation that everything else builds on. Every agent in cot_multi and full_combo uses a variant of this three-step pattern. The paper was also right that different strategies explore different regions with low overlap, which is exactly why multi-agent works.
What the paper didn’t test is what happens when you combine strategies at scale with true context isolation. 21 agents with different cognitive lenses, all unable to see each other’s work, consistently produce a more diverse pool than any single agent running a smarter prompt. At some point, adding more agents probably stops helping. I didn’t find that ceiling at 21, though the marginal gain from agent 22 was small.
The paper also didn’t test dynamically generating personas for each specific problem. This turns out to matter a lot. An addiction counselor sees habit-tracking differently than a Nintendo game designer, and both see it differently than a CoT agent with no persona. The diversity of starting perspectives is the mechanism. The complexity of any individual prompt is secondary.
Caveats
The grading was done by an LLM, not by humans. “Surprising” is subjective, and I’d expect human evaluators to disagree with the LLM grader on individual ideas while probably converging on the aggregate pattern. The test set is 5 prompts. The personas are generated fresh each time, so results will vary. I measured novelty and diversity, not idea quality or feasibility. A “surprising” idea might be surprising because it’s bad.
The benchmark script is available and reproducible. You can run it yourself and see whether the pattern holds on your own prompts.
Where I landed
I built these findings into a Claude Code skill called diverse-ideas. The default mode runs dual-agent (CoT + Informed CoT), which gives good results quickly. For serious ideation sessions, it can escalate to cot_multi with 10 dynamically generated personas and 10 creativity techniques.
The principle that makes this work isn’t specific to LLMs. Decades of organizational behavior research shows the same thing for human teams: people brainstorming independently and pooling results afterward outperform groups brainstorming together in a room. Shared context causes anchoring, whether the context is shared between people or between LLM turns. Isolation is the fix. Curation afterward is what makes it usable.
The full experiment data, benchmark script, and all grading results are in the diverse-ideas skill repository.
Paper reference: Meincke, L., Mollick, E., & Terwiesch, C. (2024). Prompting Diverse Ideas: Increasing AI Idea Variance. Wharton School Research Paper.