100,000 Agent Skills in 3 Months. Most of Them Are Untested.
In December 2025, Anthropic released the SKILL.md open standard. OpenAI adopted it for Codex CLI within days. Three months later, community registries index over 100,000 agent skills across platforms like SkillsMP (96K+), skills.sh (71K+), and ClawHub (5.7K+). Microsoft published 126 Azure agent skills. DeepLearning.AI launched a course on building them.
The growth is real. The problem is also real: most of these skills have never been tested.
What “Agent Skills” Actually Are
A skill is a directory containing a SKILL.md file with instructions (and optionally scripts, templates, and reference files) that an AI coding agent loads and follows. Think of it as a plugin. You install a skill, and your agent gains a new capability: how to write PyMC models, how to deploy to Vercel, how to run a security audit.
Skills solve the discovery problem that MCP (Model Context Protocol) doesn’t. MCP standardizes how agents talk to tools. Skills standardize how developers share and discover procedural knowledge. They’re complementary. Skills tell the agent what to do. MCP tells it how to connect.
The packaging is simple. The implications are not. Skills run with user privileges. They execute on your machine. And community registries accept submissions with minimal vetting.
The Security Problem Is Already Here
A recent academic study analyzed 98,380 skills from two major registries. The findings:
- 157 confirmed malicious skills with 632 total vulnerabilities
- Malicious skills average 4.03 vulnerabilities across a median of 3 kill chain phases
- Two attack archetypes: “Data Thieves” that exfiltrate credentials through supply chain techniques, and “Agent Hijackers” that manipulate agent behavior through instruction injection
- A single threat actor accounts for 54.1% of confirmed cases through templated brand impersonation
These aren’t theoretical risks. The ClawHavoc incident in February 2026 saw 341 malicious skills on ClawHub distributing macOS malware through legitimate-looking packages. A Snyk scan of one major registry found 7.1% of skills leak API keys through hardcoded credentials in source code.
The industry responded. Vercel partnered with Gen Digital (the Norton/Avast parent company, NASDAQ: GEN) to bring three-layer security audits to skills.sh through the Agent Trust Hub. Every skill now gets ratings from Gen’s behavioral analysis engine, Socket’s supply chain scanner, and Snyk’s vulnerability detection. That’s a serious security stack.
Security scanning is necessary. It’s also not sufficient.
The Gap Nobody Is Talking About
Security scanning answers one question: “Will this skill steal my credentials or compromise my machine?” That matters. A second question is harder, and no registry currently answers it at scale:
“Does this skill actually work?”
I can install a skill rated “Safe” by three independent security scanners. It won’t exfiltrate my API keys. It won’t install malware. But when my agent uses it to build a PyMC model, does the model specification make sense? When it generates a Terraform deployment, does the config actually deploy? When it writes tests, do they test the right things?
Security tells you a skill is safe to run. It says nothing about whether the skill is competent.
This is the eval gap. With 100,000+ skills and growing, the difference between “safe” and “good” will increasingly determine which registries developers trust for production work.
Comparing the Two Approaches
To make this concrete, compare the two registries I know best: skills.sh (Vercel) and hub.decision.ai (which we built at PyMC Labs).
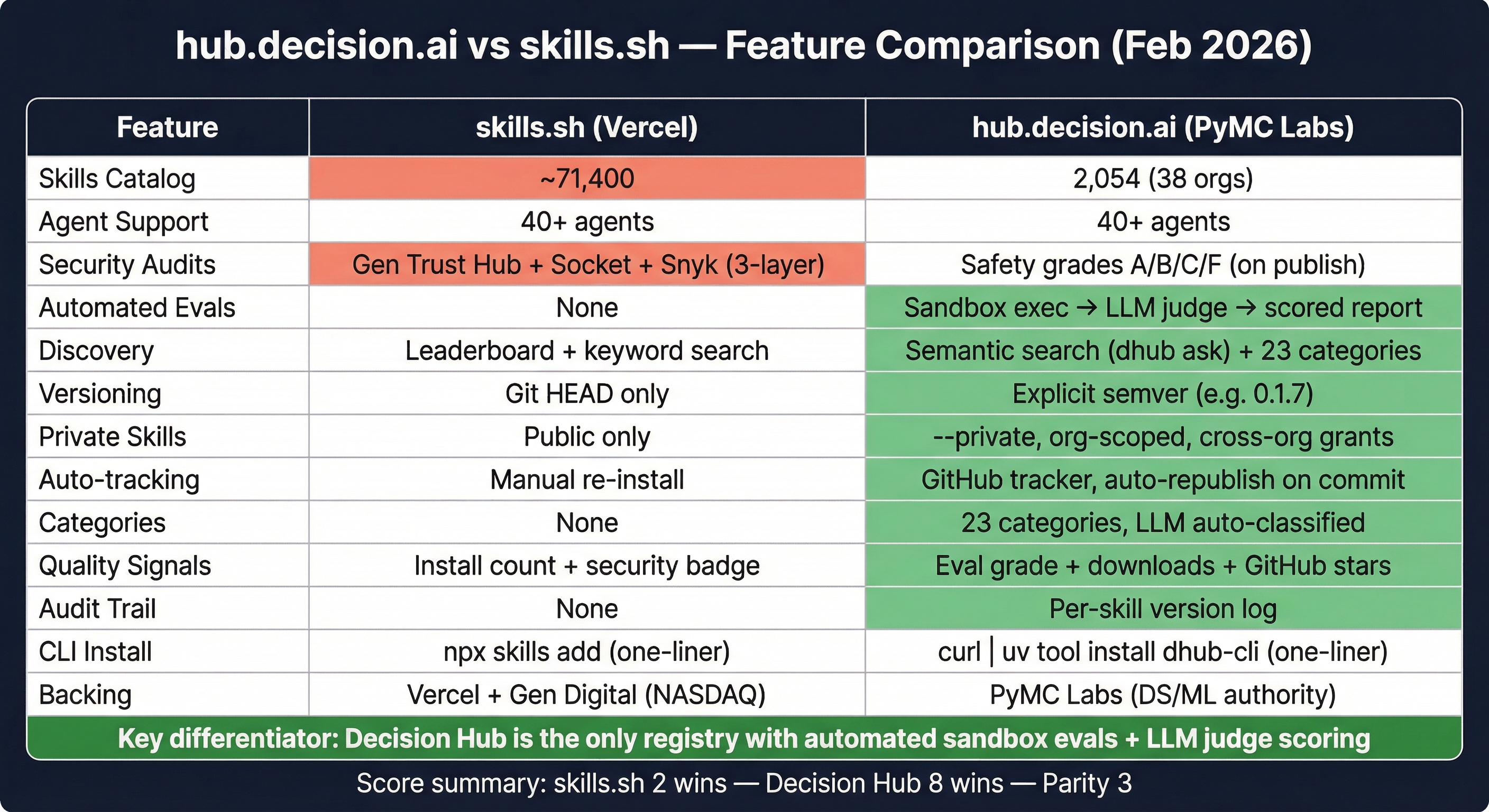
The full picture is in the table above. The short version:
Where skills.sh leads:
- Scale. 71,400 skills vs our 2,054. Vercel’s developer audience and brand make that gap hard to close.
- Security partnerships. Gen Digital’s three-layer audit (behavioral analysis + Socket + Snyk) is the strongest in the ecosystem right now.
- Zero-friction CLI.
npx skills addandcurl | uv tool install dhub-cliare both one-liners, but Vercel’s npm ecosystem reach is wider.
Where Decision Hub leads:
- Automated evals. Every skill published to Decision Hub runs through an evaluation pipeline. The skill ships with eval cases. On publish, each case executes in an isolated Modal sandbox with a real AI agent. An LLM judge scores the output against defined criteria. Pass or fail, with reasoning. Results are published as a report and feed into the skill’s safety grade (A/B/C/F). Grade F skills are rejected entirely.
- Explicit versioning.
dhub install pymc-labs/pymc-modeling:0.1.7pins a specific version. skills.sh pulls from Git HEAD, so a breaking change upstream breaks every downstream user. - Private skills and org access control. Publish with
--privateto scope skills to your GitHub organization. Grant cross-org access selectively. Enterprise teams with proprietary modeling workflows need this. - Open source and self-hostable. Decision Hub is open source (link available soon). Organizations that need to keep skills, evals, and agent interactions behind their own firewall can self-host the entire platform — registry, eval pipeline, and all.
- Semantic search.
dhub ask "how do I analyze A/B test results?"uses embeddings for intent-based discovery. skills.sh has keyword search and a popularity leaderboard. - 23 auto-classified categories. LLM classification on publish, with category-filtered browsing and sort by downloads or recency.
- GitHub auto-tracking. Publish from a GitHub URL once, and a tracker automatically republishes when commits land. No CI setup required.
The feature scoreboard is lopsided. skills.sh wins on catalog size and security partnerships. Decision Hub wins on evals, versioning, private skills, discovery, categories, auto-tracking, quality signals, and audit trail.
Scale and depth serve different users. skills.sh has Vercel’s distribution engine and broad frontend coverage. Decision Hub has PyMC Labs’ deep roots in data science and ML — the community that needs quality assurance most, because wrong model output costs real money. If you’re building React apps, skills.sh is the natural choice. If you’re building statistical models, running experiments, or making data-driven decisions, Decision Hub is where the domain expertise and eval infrastructure live.
Why Evals Are the Key Differentiator
The skills ecosystem is following the same trajectory as every other software package ecosystem. First comes growth (npm had 1 million packages by 2019). Then comes security (npm audit, Snyk, Socket). Then comes quality (test coverage, type safety, maintained vs abandoned).
We’re in the security phase right now. The quality phase is starting. Evals are how it starts.
A skill eval is structurally simple. The skill author defines test cases: a prompt, and criteria for what “good” output looks like. On publish, Decision Hub spins up an isolated sandbox, installs the skill into a real agent, runs each test case, and has an LLM judge evaluate whether the output meets the criteria. The whole pipeline streams results with S3 persistence and database heartbeats for reliability.
This isn’t a toy. It’s the same pattern that made CI/CD the standard for software quality. You don’t merge code without tests passing. Eventually, you won’t install skills without evals passing.
The registries that build this infrastructure now will be the ones that enterprise teams trust when they start deploying agent skills in production. And that transition from “developer experimentation” to “production deployment” is where the real value concentrates.
Where This Goes Next
Three predictions for the next 12 months:
1. Consolidation around 2-3 major registries. The current fragmentation (SkillsMP, skills.sh, ClawHub, Decision Hub, awesome-lists, and dozens more) isn’t sustainable. Developers will converge on registries that combine catalog breadth, security, and quality signals. The rest become mirrors or die.
2. Enterprise features become the monetization layer. Private skills, org-level access control, audit trails, and self-hosted options are what enterprise teams will pay for. The public registry stays free. The enterprise tier generates revenue.
3. Evals become table stakes. Just as no serious npm package ships without tests today, skill authors will be expected to include eval cases. Registries that don’t support automated evaluation will be seen as the “pre-CI” era of package management.
The agent skills ecosystem is three months old and already has 100,000+ packages, a real security problem, and an active solution emerging. The question isn’t whether this ecosystem matters. It’s whether quality assurance can keep up with growth.
We’re building Decision Hub because we think the answer is evals, not just scans. Try it yourself and tell me if we’re right.
Luca Fiaschi is a Partner at PyMC Labs and co-creator of Decision Hub. He writes about AI, decision systems, and the craft of building things that work in production.